Architecture DeepSeek V4
OCR 2 Vision
MoE Visuel-Langage. Compréhension au pixel près de documents complexes.
Share:
Qu'est-ce que OCR 2 ?
DeepSeek OCR 2 représente un changement de paradigme dans la compréhension visuelle de documents. Il utilise la nouvelle architecture « DeepEncoder V2 », qui découple la compréhension visuelle de la génération. Il est entraîné pour comprendre les documents dans un ordre de lecture humain, lui permettant de reconstruire parfaitement des mises en page complexes, des tableaux imbriqués et des formules mathématiques à partir de pixels vers Markdown/LaTeX.
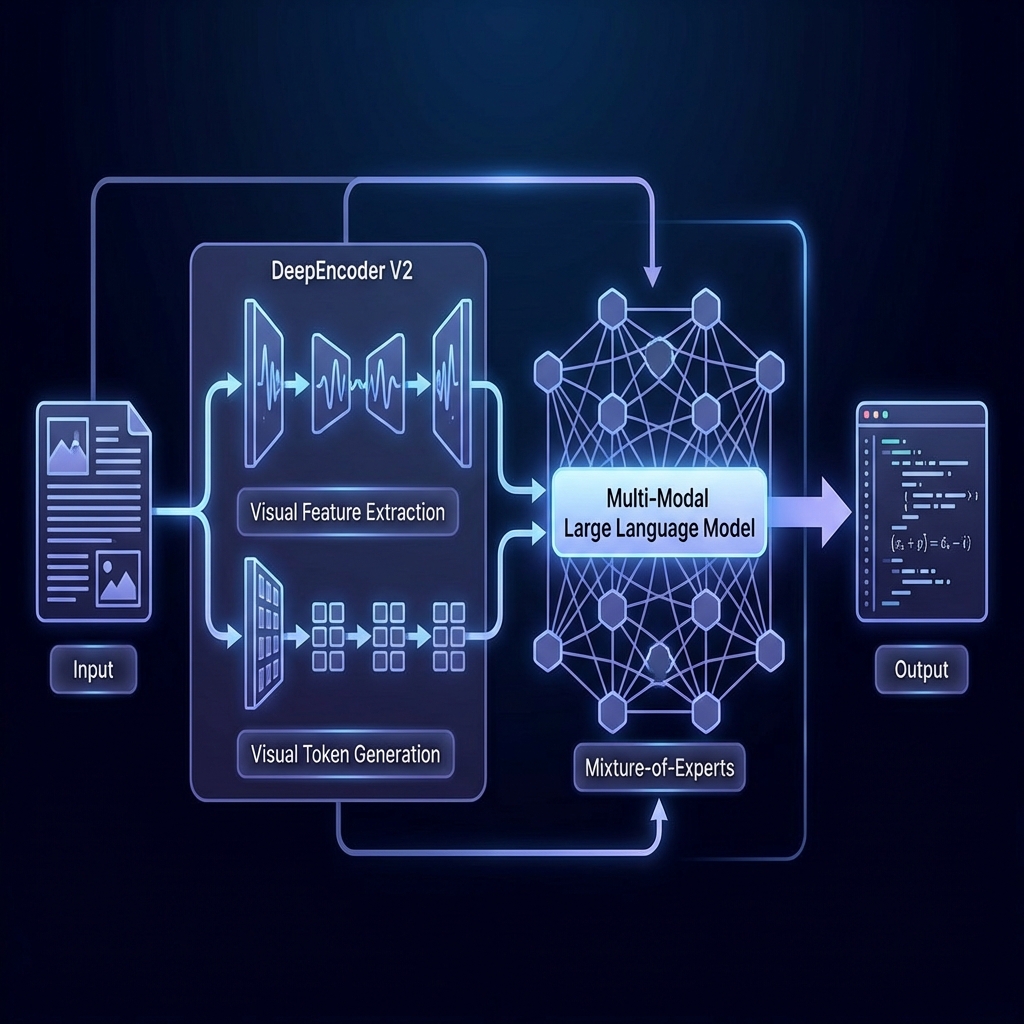
Figure 1 : OCR Standard vs DeepEncoder V2
OCR 1.0 vs OCR 2.0
DeepSeek OCR 1.0
Détection de boîte englobante. Lutte avec les mises en page complexes et l'écriture manuscrite.
DeepSeek OCR 2.0
Modèle Visuel-Langage de bout en bout. 91% de Précision. Gère toute mise en page, écriture manuscrite et formule.
Score OmniDocBench
Tuilage Dynamique & Janus-Pro
OCR 2 utilise une stratégie de « Tuilage Dynamique » pour traiter des entrées haute résolution de tout format sans distorsion. Il est propulsé par le framework Janus-Pro, qui utilise des encodeurs séparés pour l'extraction de caractéristiques visuelles (SigLIP) et la génération de jetons visuels (VQ), assurant à la fois une haute compréhension sémantique et une reconstruction précise des détails.
Questions Fréquemment Posées
Share:
Lectures connexes
Obtenir les fuites V4
Rejoignez 50 000+ développeurs qui suivent V4.