DeepSeek V4 Architektur
OCR 2 Vision
Visual-Language MoE. Pixelgenaues Verständnis komplexer Dokumente.
Share:
Was ist OCR 2?
DeepSeek OCR 2 stellt einen Paradigmenwechsel im visuellen Dokumentenverständnis dar. Es nutzt die neue 'DeepEncoder V2'-Architektur, die das visuelle Verständnis von der Generierung entkoppelt. Es ist darauf trainiert, Dokumente in einer menschenähnlichen Lesereihenfolge zu verstehen, was es ihm ermöglicht, komplexe Layouts, verschachtelte Tabellen und mathematische Formeln von Pixeln zu Markdown/LaTeX perfekt zu rekonstruieren.
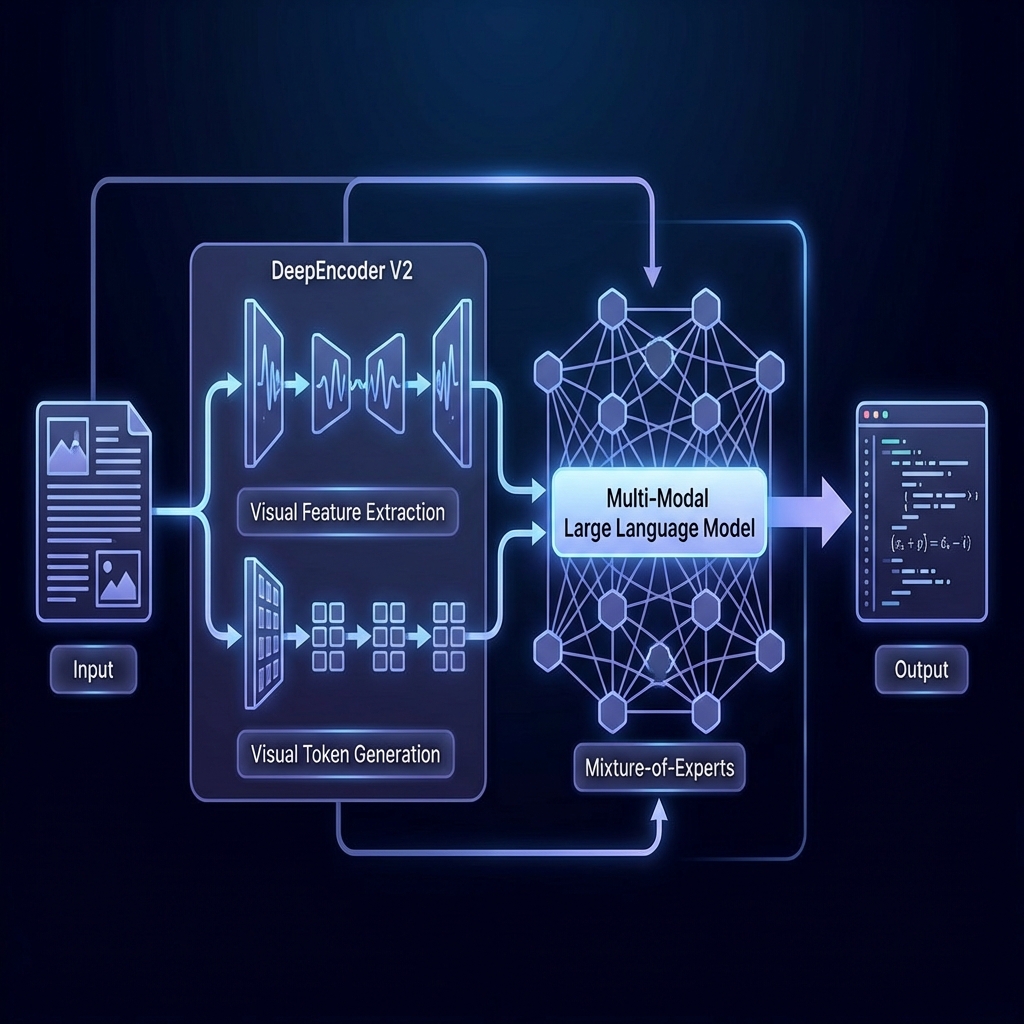
Abbildung 1: Standard OCR vs. DeepEncoder V2
OCR 1.0 vs. OCR 2.0
DeepSeek OCR 1.0
Bounding-Box-Erkennung. Hat Schwierigkeiten mit komplexen Layouts und Handschrift.
DeepSeek OCR 2.0
End-to-End Visual-Language Model. 91% Genauigkeit. Bewältigt jedes Layout, Handschrift und Formeln.
OmniDocBench Ergebnis
Dynamisches Tiling & Janus-Pro
OCR 2 verwendet eine 'Dynamic Tiling'-Strategie, um hochauflösende Eingaben beliebigen Seitenverhältnisses ohne Verzerrung zu verarbeiten. Es wird vom Janus-Pro-Framework angetrieben, das separate Encoder für die visuelle Merkmalsextraktion (SigLIP) und die visuelle Token-Generierung (VQ) verwendet, was sowohl ein hohes semantisches Verständnis als auch eine präzise Detailrekonstruktion gewährleistet.
Häufig gestellte Fragen
Share:
Verwandte Lektüre
V4 Leaks erhalten
Schließen Sie sich 50.000+ Entwicklern an, die V4 verfolgen.