DeepSeek V4 Architecture
OCR 2 Vision
Visual-Language MoE. Pixel-perfect understanding of complex documents.
Share:
What is OCR 2?
DeepSeek OCR 2 represents a paradigm shift in visual document understanding. It utilizes the new 'DeepEncoder V2' architecture, which decouples visual understanding from generation. It is trained to understand documents in a human-like reading order, enabling it to perfectly reconstruct complex layouts, nested tables, and mathematical formulas from pixels to Markdown/LaTeX.
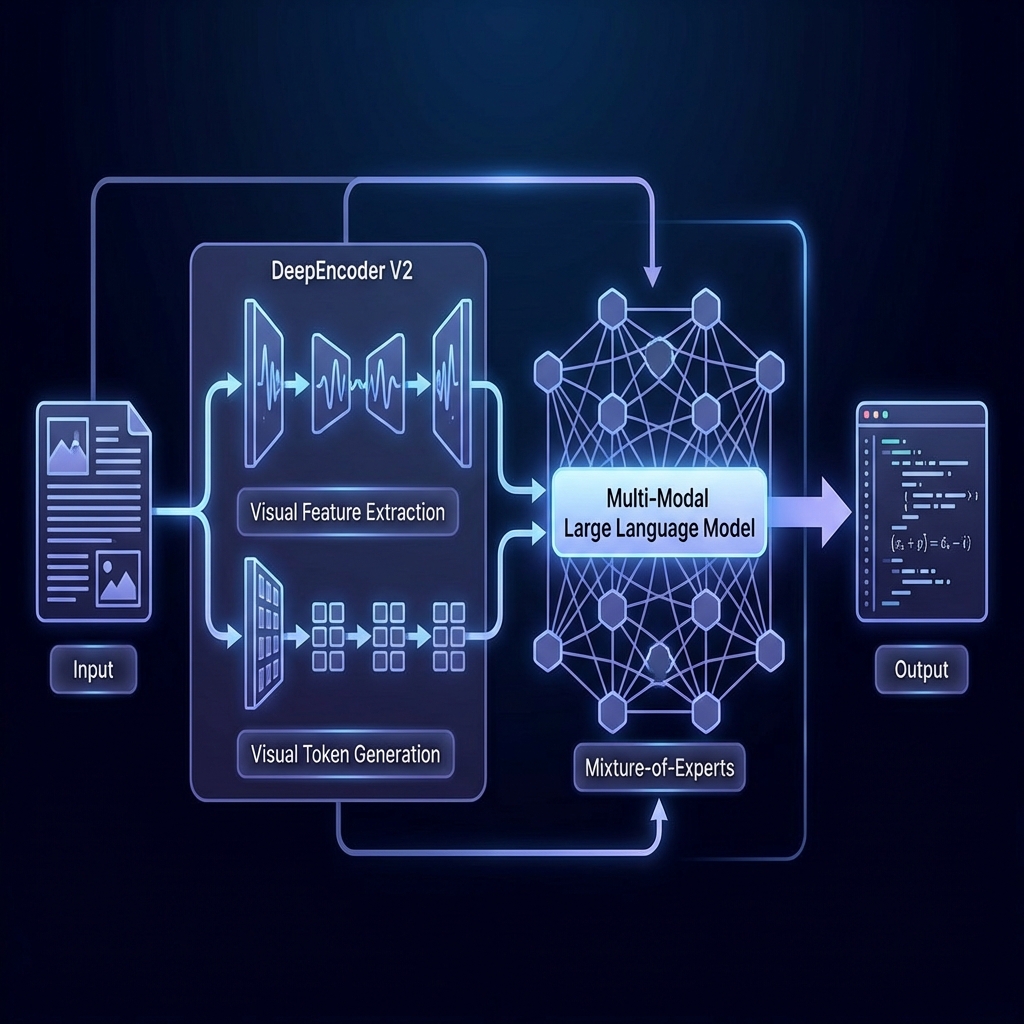
Figure 1: Standard OCR vs DeepEncoder V2
OCR 1.0 vs OCR 2.0
DeepSeek OCR 1.0
Bounding box detection. Struggles with complex layouts and handwriting.
DeepSeek OCR 2.0
End-to-End Visual-Language Model. 91% Accuracy. Handles any layout, handwriting, and formula.
OmniDocBench Score
Dynamic Tiling & Janus-Pro
OCR 2 employs a 'Dynamic Tiling' strategy to handle high-resolution inputs of any aspect ratio without distortion. It is powered by the Janus-Pro framework, which uses separate encoders for visual feature extraction (SigLIP) and visual token generation (VQ), ensuring both high semantic understanding and precise detail reconstruction.
Frequently Asked Questions
Share:
Related Reading
Get V4 Leaks
Join 50,000+ developers tracking V4.